
Ruff, a ridiculously fast Python linter, has been gaining some serious traction recently. No wonder as it's providing close to feature parity with a dozen of linting tools most of which were previously the go-to for the majority of Python projects. Not only it provides all this within a single tool but it's also orders of magnitude faster than the predecessor. The remarkable speed gains are thanks to Ruff being written in Rust.
I recently migrated one of my open source projects, pytest-split, to use Ruff as a replacement for Flake8, isort, pyupgrade, and autoflake. In this blog post, I'll share the experience from the migration exercise as well as discuss the key features and maturity of Ruff. I believe Ruff is quickly becoming the linter of the Python community.
Example migration
I recently migrated one of my open source projects, pytest-split, to use Ruff. Although pytest-split has a relatively small codebase, the migration process is would be likely similar also for bigger codebases. Here's the relevant pull request. Roughly, these were the steps taken:
-
Added
ruffto dev dependencies and removed the ones that Ruff replaces.

-
Added a Ruff entry to pre-commit configuration and removed the entries of the tools it replaces.
-
Removed the configs of the old tools, such as Flake8 configuration (setup.cfg in my case). There's also
flake8-to-ruffwhich can be used for migrating existing Flake8 configuration. My configuration was so simple that I decided to start from a clean table. -
Configured Ruff.
pytest-splitis using pyproject.toml which Ruff supports ([tool.ruff]section). Note that the default configuration of Ruff only enables"E"(pycodestyle) and"F"(Pyflakes) rules. As my personal taste is strict, I enabled all the available rules withselect = ["ALL"]. -
Ran
ruff check .and got greeted with 200+ errors. So, it's indeed strict when all the rules are enabled. -
I skimmed through the errors and added the ones I didn't agree with to the
ignorelist with comments for each. Additionally, I added a couple of inlinenoqas for the cases in which I didn't want to ignore a rule on the global level. -
At this point
ruff check .showed a dozen errors which all where automatically fixable.
- Ran
ruff check . --fixand it politely fixed all the remaining ones. - Finally checked that
ruff check .andpre-commitdon't show errors.
And that was it! Around half an hour later, I was an extremely happy Ruff user. The CI of pytest-split is using pre-commit for linting (pre-commit run --all-files), so I didn't need to touch any of the Github Actions workflows.
Features
While writing this (4/2023), Ruff is v0.0.261 and is currently actively developed so there might be additional features if you're reading this in the future.
Speed
Speed is probably the biggest selling point of Ruff. It claims to be "10-100x faster than existing linters". I haven't run any benchmarks myself but it sure is ridiculously fast with the pytest-split codebase. If you're interested about benchmarks, there are some documented in the docs. The larger the codebase, the more you'll benefit from the speed gains. In addition to Ruff being powered by Rust, it has a caching system which speeds up consecutive runs.
Feature parity with older tools
Most notably, Ruff can be used as a replacement for Flake8, isort, pydocstyle, yesqa, eradicate, pyupgrade, and autoflake. If we also count all the Flake8 plugins for which Ruff has a native re-implementation, there are around 50 Python packages whose features Ruff covers. See the full list in the docs.
Considering the whole Python ecosystem, I believe Ruff paves the way for newcomers to adopt best practices, and thus helps them to produce high quality code sooner compared to the pre-Ruff era. Also, considering more seasoned Python developers, a notable simplification to the existing toolset is certainly very welcome. In my case, after migrating to Ruff, the core code hygiene tooling jungle shrunk from a dozen different tools to 3: Black for auto-formatting, Ruff for linting, and mypy for static type checking.
Other goodies
In addition to the linting capabilities, Ruff is also capable of fixing some of the issues it detects (see steps 7 & 8 in the example migration above).
There's support for running Ruff continuously by using a --watch command line option which basically tracks file changes and re-runs when changes are detected.
Ruff is monorepo-friendly: it's possible to have multiple pyproject.toml (with a [tool.ruff] section in each) in different levels of a codebase. Ruff is able to pick up the configuration from the closest pyproject.toml.
Maturity
Until February 2023, Ruff lacked support for pattern matching, a feature introduced in Python 3.10, which was a showstopper for many considering Ruff adoption. Luckily, that got fixed (relevant issue) and currently Ruff claims to be compatible with 3.11, i.e. the latest and greatest Python.
The list of projects using Ruff showcases the current state of adoption. For example, Apache Airflow, FastAPI, pandas, and pydantic are already using Ruff. Fun fact, also Pylint is using Ruff as a pre-commit hook. At the time of writing, GitHub shows that Ruff is used by 2.7k (open source) projects.
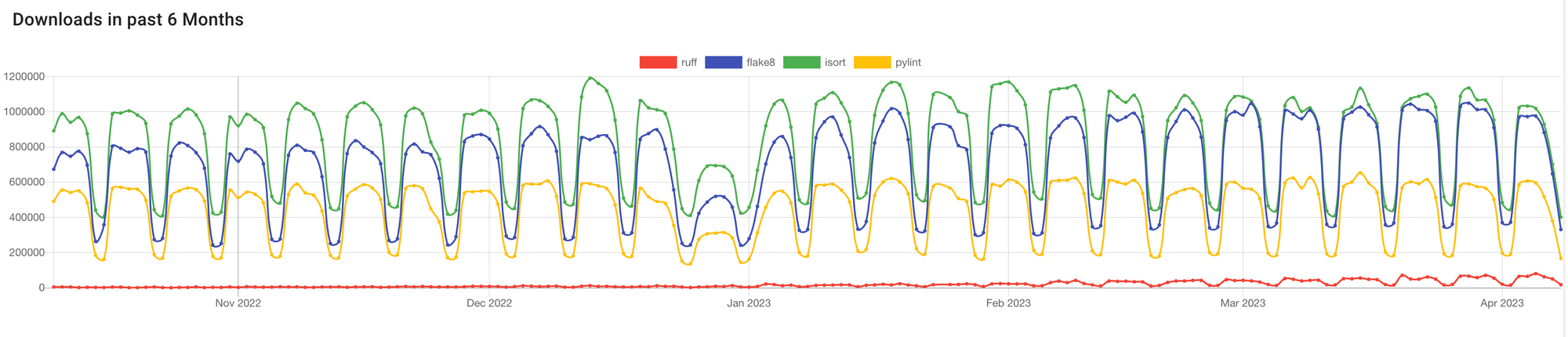
For now, Ruff is nowhere near Flake8, isort, and Pylint in download counts but the momentum is clearly visible in this pip trends graph:
Future
I believe Ruff is becoming the de facto linting tool of the Python community and that it'll slowly replace the usage of the older tools. It'll be interesting to see how the pip trends graph looks a year from now.
I also believe that having all the linting bells and whistles in a single package which is backed by a strong community will be beneficial considering the adoption of new Python versions. For example, there has been multiple occasions in the past in which a new Python release had been out for months but some of the linting related packages hadn't yet added support for the new language features. I hope the future will be brighter with Ruff.
Learn more
- Ruff docs
- Charlie Marsh, the author of Ruff, as a guest in the Talk Python To Me podcast
- PyCharm by JetBrains webinar about Ruff



