
- You are working on a shiny Flask app which relies on SQLAlchemy for ORM and utilizes Alembic for database schema migrations
- There are multiple contributors in the project
- Every now and then the alembic upgrade command fails to something like "... multiple head revisions ..."
Sounds familiar? Keep reading.
How do we end up there
The illustrations below represent migration graphs (basically the output of alembic history commands). Each node represents a single alembic revision and an arrow between two nodes denotes a link between two revisions. Green color implies the currently deployed revision, i.e. alembic current in the deployment environment. For example, in the Image 1, the down revision of B is A whereas C is the head revision and it's also the current revision in the deployment environment.
If you are the only developer in the project, the graph usually looks like a train: no branches. Your alembic upgrades also work like most of trains: no problems.
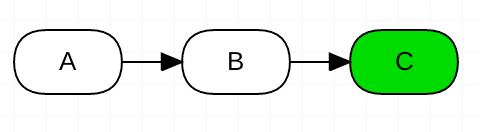
If there are multiple collaborators in the project, the following scenario is what will eventually happen. Dev1 works on her shiny new feature in her feature branch. As she has changed the models, she creates a new migration D. The down revision of D is C which is the currently deployed version in the test environment and in production.
Meanwhile, Dev2 works on his shiny new feature and creates two new migrations in his feature branch: E and F.
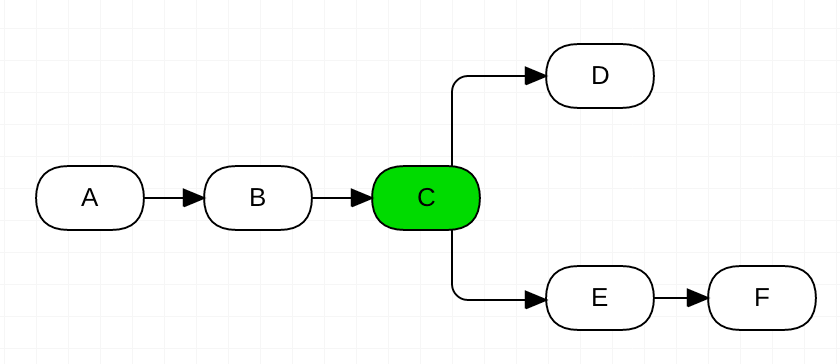
Dev1 finishes her work faster than Dev2. D is merged to master, continuous integration runs, tests pass, continuous deployment runs, alembic upgrade is successful, life is great, the whole office drinks champagne.
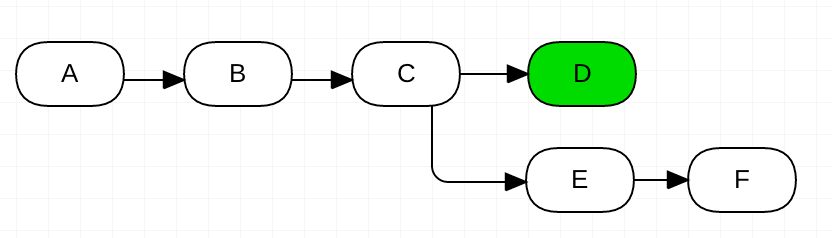
Then Dev2 finishes his work and his feature branch gets merged. Continuous integration runs, tests pass, continuous deployment runs, alembic upgrade runs...

alembic.util.exc.CommandError: Multiple head revisions are present for given argument 'head'; please specify a specific target revision, '@head' to narrow to a specific head, or 'heads' for all heads
Deployment fails, red lights start flashing, five developers start investigating what went wrong, the whole office is in chaos, nobody drinks champagne.
What to do
Firstly, let's have a look at what would be the output of alembic history in the master branch after the work of Dev2 is merged.
E -> F (head), some message
C -> E, some message
C -> D (head), some message
B -> C (branchpoint), some message
A -> B, some message
<base> -> A, some message
As you can see, there is a branchpoint followed by two heads: we are facing a multi-headed monster.
Option 1: change the down revision of E manually (the hacky way)
If we change the down revision of E from C to D, we get a smooth train-like graph. However, in my opinion, this is not the preferred workaround as it'll at least easily mess up the local development database of Dev2 if he doesn't fully understand what's going on.

alembic history would give:
E -> F (head), some message
D -> E, some message
C -> D, some message
B -> C, some message
A -> B, some message
<base> -> A, some message
Option 2: create a merge migration (the good way)
This is the preferred way. In the example scenario, migration merge script can be generated simply by:
alembic merge heads -m "merge D and F"
Or if you are facing more than two heads, you may want to be explicit about which heads to merge and do something like:
alembic merge D F -m "merge D and F"
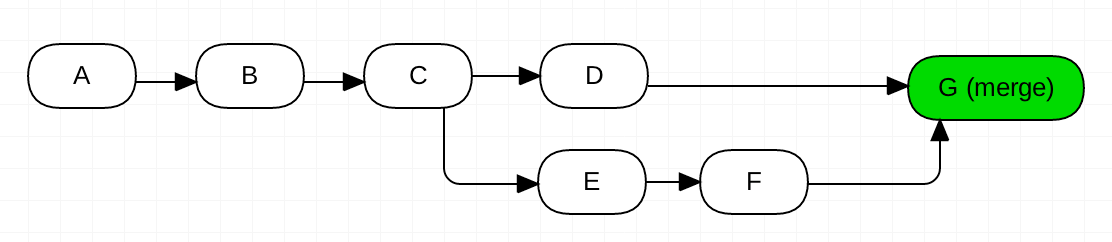
In this case, alembic history would yield:
D, F -> G (head) (mergepoint), merge D and F
E -> F, some message
C -> E, some message
C -> D, some message
B -> C (branchpoint), some message
A -> B, some message
<base> -> A, some message
When to do it
Ideally Dev2 is aware of the work done by Dev1 and keeps his feature branch up to date with the master branch. This way he would have probably spotted the issue before creating the pull request to master.
However, if Dev2 did not follow what Dev1 had been up to (like in the example scenario), at least the person responsible for accepting the pull request should be aware of the situation. In practice, the more contributors and pull requests there are, the trickier it gets. We are just humans.
Thus, the best option - like always - is to not rely on people if we can rely on automation.
Protect your team against multi-headed monsters - add a unit test to detect them!
Spotting the issue during CI tests (or even during local test suite runs) is obviously a better alternative compared to running into the issue during deployment. Failure during deployment may even have some nasty side effects (of course ideally should not) while failed tests won't suffer from those (unless something is done completely wrong).
from alembic.config import Config
from alembic.script import ScriptDirectory
def test_only_single_head_revision_in_migrations():
config = Config()
config.set_main_option("script_location", "my_fancy_app:migrations")
script = ScriptDirectory.from_config(config)
# This will raise if there are multiple heads
script.get_current_head()
In case of a multi-headed monster, the test will fail with an output similar to this:
alembic.util.exc.CommandError: The script directory has multiple heads (due to branching).Please use get_heads(), or merge the branches using alembic merge.
Final tips
- Be sure to understand the output of alembic history
- Sketching things on a piece of paper may be helpful
- It's better to check alembic history and alembic current too often
- Make sure alembic downgrade runs without issues (in addition to upgrade) when you create new migrations
- Give your migrations some human understandable meaning by specifying the message with -m flag



